WindowsでMeCab+NEologdを使用する際に結構てこずったので大まかな流れと自分なりの対処法を残しておきます。
MeCabとは
MeCabとは形態素解析と呼ばれる、文章を単語に分解してくれるパッケージです。Pythonからも利用できます。
NEologdは新語辞書というものらしいです。こちらをMeCabと組み合わせることで近年新たに使用されるようになった単語に対応することができるようになります。
具体的には以下のような結果になります。
「機械学習について説明します。」という文章を単語に分割する場合


2つの結果を見比べてもらうと、「機械学習」という単語がMeCabのみでは「機械」と「学習」に分割されているのに対して、MeCab+NEologdで単語分割すると「機械学習」という固有名詞として認識されています。
日本語は英語等と違って、簡単に単語の切れ目を見分けることができないため、あらかじめ用意されている形態素解析パッケージ等により文章を単語に分割して機械学習に用いることが多いようです。
MeCab+NEologdのインストール方法
こちらの作業は下記のサイトを参考に行いました。
参考サイト
https://qiita.com/zincjp/items/c61c441426b9482b5a48
https://qiita.com/zincjp/items/55960801d99e55c9f2a6
まず前提として、この記事はWindows上でAnacondaをPython実行環境として使用しています。
使用するマシンのOSの話とか、PythonとかAnacondaについてはまた別途書きたいと思います。
”リンク予定地”
MeCabをインストール
公式サイトからMeCabをダウンロード、インストールします。
http://taku910.github.io/mecab/#download
このあたりが公式らしいです。また、さらに上に張った参考サイトリンク先を見てもらうと野良の有志で作成された64Bit版があるようです。
今回私は参考サイトの勧め通り64Bit版を使用しました。
ただし、64Bit版を使用する場合にも32Bit版をインストールしましょう。
32Bit版のみ、インストール時に文字コードの種類を聞かれるので、”UTF-8″を選択します。
(64Bit版で文字コードを聞かれた場合は32Bit版は不要かもしれません。)
インストールしたら環境変数のPATHに下記を追加します。
(環境変数の変更の仕方は下の方に記載しておきます。)
C:\Program Files\MeCab\bin
下線部はインストール場所により異なります。32Bit版の場合
C:\Program Files (x86)
がデフォルトになっていると思います。
次にMeCabをPythonで使用するためのパッケージをインストールするために、AnacondaPromptに下記のように打ち込みます。
(AnacondaPromptはWindowsスタートメニューの、プログラム一覧のAnacondaフォルダ内にあると思います。)
pip install mecab-python-windows
インストールの確認
インストールが完了したら、
(MeCabのインストール先)/binにある”libmecab.dll”というファイルを
(Anacondaのインストール先)/Lib/site-packages
にコピーするという風になっていますが、私の環境ではすでにファイルが存在したため、そのままにしました。
インストールが上手くいった確認作業として、jupyternotebook等で
import mecab
と入力、実行してエラーが出なければ無事MeCabのインストール完了です。
NEologdのインストール
NEologdのダウンロード
こちらも参考サイトに従い、NEologdをダウンロードしてきます。
参考サイトでは git for windows を使用してダウンロードする方法が載っていますので、そちらを参考にしてみてもよいと思います。
私はgitの使用方法に疎いので、直接GitHubにブラウザでアクセスして、右側のClone or DownloadからZipをダウンロードしました。
GitHub URL: https://github.com/neologd/mecab-ipadic-neologd.git
ZIPファイルを解凍すると”mecab-ipadic-neologd-master”というフォルダができると思います。
参考サイトを見ると、正しいgit操作では”mecab-ipadic-neologd”となるようなので、”-master”が余計です。
フォルダ名を変更するなり、読み替えるなりしてください。
このフォルダは作業後は使用しないので、その辺りは適当で大丈夫です。
なお、ここからの作業はコマンドプロンプトを使用するので、解凍したフォルダはプロンプトのホームディレクトリ直下に移動しておくことをお勧めします。
辞書ファイルのコンパイル準備
以降は(ホームディレクトリ)/mecab-ipadic-neologdに移動して名前を変更したものとして説明していきます。
以下の作業で.xzファイルを解凍しなければいけないので、解凍ソフトの7-Zipをインストールしておきましょう。
.xzファイルを解凍できるソフトがインストールされていればそちらでも大丈夫です。
7-Zipダウンロードサイト: https://sevenzip.osdn.jp/
コマンドプロンプトを起動し、以下のように打ち込んでディレクトリを移動します。
cd mecab-ipadic-neologd\seed
こちらの”seed”フォルダに入っている.xzファイルをすべて解凍します。
コマンドプロンプトで解凍する場合には
7z X *.xz
と打ち込めば解凍できるようです。
もしくはエクスプローラでフォルダを開き、.xzファイルを選択して「右クリック→7-Zip→ここに展開」でも解凍できます。
UFT-8形式辞書のコンパイル
解凍出来たら”c:\Program Files (x86)\MeCab\dic\ipadic”フォルダを同じ”dic”フォルダ内にコピーして、フォルダ名を”ipadic-UTF8″に変更してください。
“seed”フォルダをカレントディレクトリにして(これまでの作業をしていれば自然とカレントディレクトリになっています。)、下記のように打ち込みます。
(表示の問題で改行が入っている場合がありますが、一行で続けて入力してください。)
○○は20190128等の日付が入ります。mecab-user-dict-seed.○○.csvというファイルが”seed”フォルダ内にあるはずですのでそちらの日付を打ち込んでください。64 Bit版の場合は”c:\Program Files (x86)”が”c:\Program Files”になります。
mecab-dict-index -d “c:\Program Files (x86)\MeCab\dic\ipadic-UTF8” -u NEologd.○○-u.dic -f utf-8 -t utf-8 mecab-user-dict-seed.○○.csv
これでUTF-8形式の辞書ファイルができました。
64 Bit版で文字コードを指定せずにインストールされた場合は解凍したCSVファイルの中身がSHIFT-JISになっていて辞書ファイルのコンパイルが不完全になるようです。
参考サイトのリンク先に「WindowsでNEologd辞書を比較的に簡単に入れる方法-システム辞書編」というページに「SHIFT-JIS形式のファイルをUTF-8に変換する。」という項目があるので、そちらを参考にしてみてください。
面倒な方は32Bit版で作業を行い、最後に出来上がったファイルを64Bit版のフォルダにコピーする方法をお勧めします。
“seed”フォルダ内に出来上がった”NEologd.○○-u.dic”ファイルを”C:\Program Files (x86)\MeCab\dic\NEologd”フォルダに移動します。
“NEologd”フォルダは存在していないと思うので、作成してください。
このとき”c:\Program Files (x86)”を”c:\Program Files”にすれば64Bit版でも使用できると思います。その場合、作成した”ipadic-UTF8″フォルダも”c:\Program Files\MeCab\dic”フォルダ内に移動してください。
SHIFT-JIS形式辞書のコンパイル
同様にSHIFT-JIS形式の辞書ファイルも作ります。
SHIFT-JIS形式の辞書はpythonでMeCab+NEologdを使用する分には必要ないように思います。下の辞書フォルダの設定まで読み流してもらっても大丈夫です。
“seed”フォルダをカレントディレクトリにして(これまでの作業をしていれば自然とカレントディレクトリになっています。)、下記のように打ち込みます。
mecab-dict-index -d “c:\Program Files (x86)\MeCab\dic\ipadic” -u NEologd.○○.dic -f utf-8 -t shift-jis mecab-user-dict-seed.○○.csv
〇〇は上と同様に日付に読み替えてください。
“seed”フォルダ内に出来上がった”NEologd.○○.dic”ファイルを”C:\Program Files (x86)\MeCab\dic\NEologd”フォルダに移動します。
辞書フォルダの設定(UTF-8)
辞書フォルダの設定をします。
“C:\Program Files (x86)\MeCab\etc”フォルダ内にある”mecabrc”の名前を”mecabrc-u”に変更します。
“C:\Program Files (x86)\MeCab\etc”フォルダはセキュリティ設定が編集不可になっている場合があります。その場合はフォルダのプロパティからセキュリティを変更してを編集可にしてください。
“mecabrc-u”メモ帳で開きます。(拡張子がないので使用するプログラムを聞かれると思います。)
開いた”mecabrc-u”に下記の2行を追加してください。
64Bit版を使用する場合は”Program Files (x86)”を”Program Files”に変更してください。
dicdir = C:\Program Files (x86)\MeCab\dic\ipadic-UTF8
userdic = C:\Program Files (x86)\MeCab\dic\NEologd\Neologd.○○-u.dic
ファイルを上書き保存します。
ここで、参考サイトでは”dicdir = $(rcpath)..\dic\ipadic-UTF8″と書かれていますが、これを上手くプログラムが処理できず、実行するとエラーとなるようです。上記の通り絶対パスで指定すれば大丈夫です。
辞書フォルダの設定(SHIFT-JIS)
SHIFT-JISの辞書ファイルもコンパイルした場合はこちらも同様に設定してください。
“C:\Program Files (x86)\MeCab\etc”フォルダ内にある”mecabrc”メモ帳で開き、下記の2行を追加します。
dicdir = C:\Program Files (x86)\MeCab\dic\ipadic
userdic = C:\Program Files (x86)\MeCab\dic\NEologd\Neologd.○○.dic
ファイルを上書き保存します。
動作の確認
動作を確認します。
コマンドプロンプトを起動して
mecab -r “C:\Program Files (x86)\MeCab\etc\mecabrc-u”
と打ち込んでエラーメッセージが出なければ上手く動作すると思います。
64Bit版を使用する場合は”C:\Program Files (x86)”を”C:\Program Files”に変更してください。
PythonでMeCab+NEologdを使用する。
ここまでやって、ようやくインストールが完了しましたが、実はこのままではPythonでMeCab+NEologdを使用することができません。
(私の環境ではできませんでした。)
PythonでMeCab+NEologdを使用する場合、
#動作しません
import MeCab
m=MeCab.tagger(“-r C:\Program Files (x86)\MeCab\etc\mecabrc-u”)
print(m.parse(“機械学習の説明をします。”)
とすればよいのですが、実はここで問題が2つほどあります。
- \(バックスラッシュ)が文字列内にあるため特殊文字と認識される。
- ファイルパス内にスペースが入っているため、MeCabにアーギュメントを渡す際に区切られてしまう。
ひとつめは、\(バックスラッシュ)が文字列の中に入っているとその直後の文字と合わさって特殊な1文字となります。これを回避するために、
- “/”を使用する。
- “\\”を使用する。(文字”\”を表す特殊文字になります)
のどちらかを行えば上手く動作しました。
ふたつめのスペースは割と深刻で、私には解決策がわかりませんでした。
結局”mecabrc-u”ファイルをパスにスペースを含まない場所に移動して実行することで対応することにしました。
こちらについてはあまり役に立っていませんが、何かの参考になればと思います。
以上、本筋ではないですが、苦労して分かったこともありますので、ここに残しておきたいと思います。
おまけ:環境変数の設定方法(Windows10)
環境変数の設定方法を載せておきます。
環境変数は編集を失敗すると他のプログラムが正常に動作しなくなる場合があります。設定は自己責任でお願いします。
まず、スタートボタンからWindowsの設定を開きます。(歯車マーク)
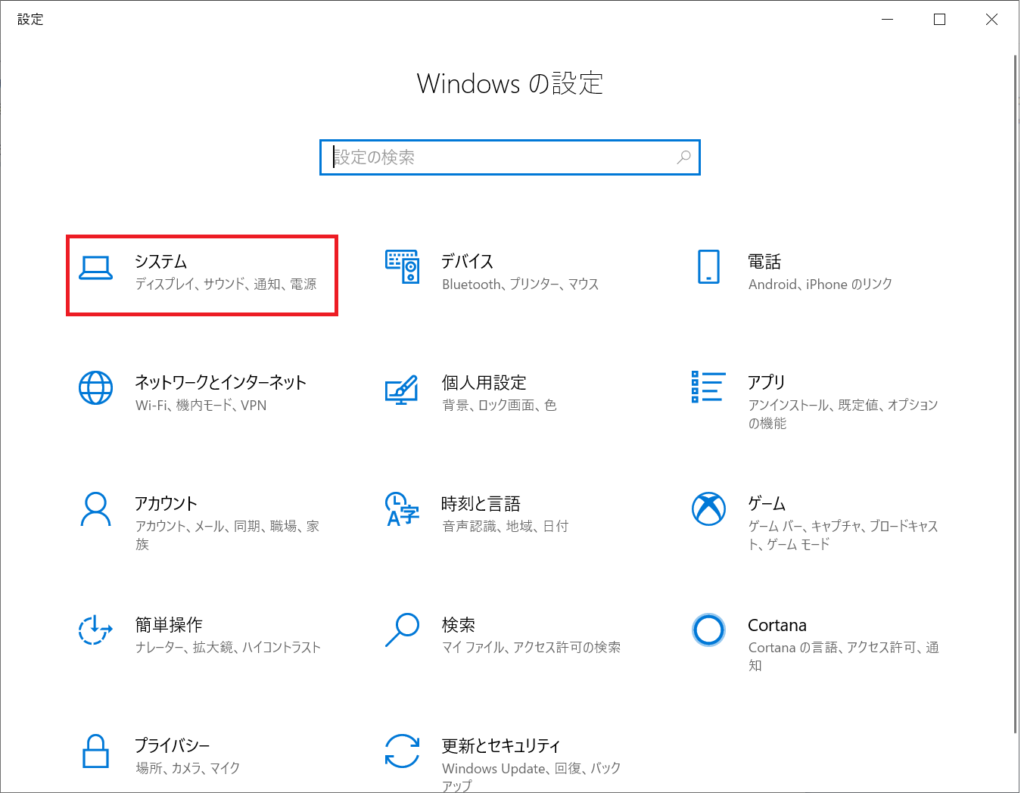
設定の中の「システム」を開きます。
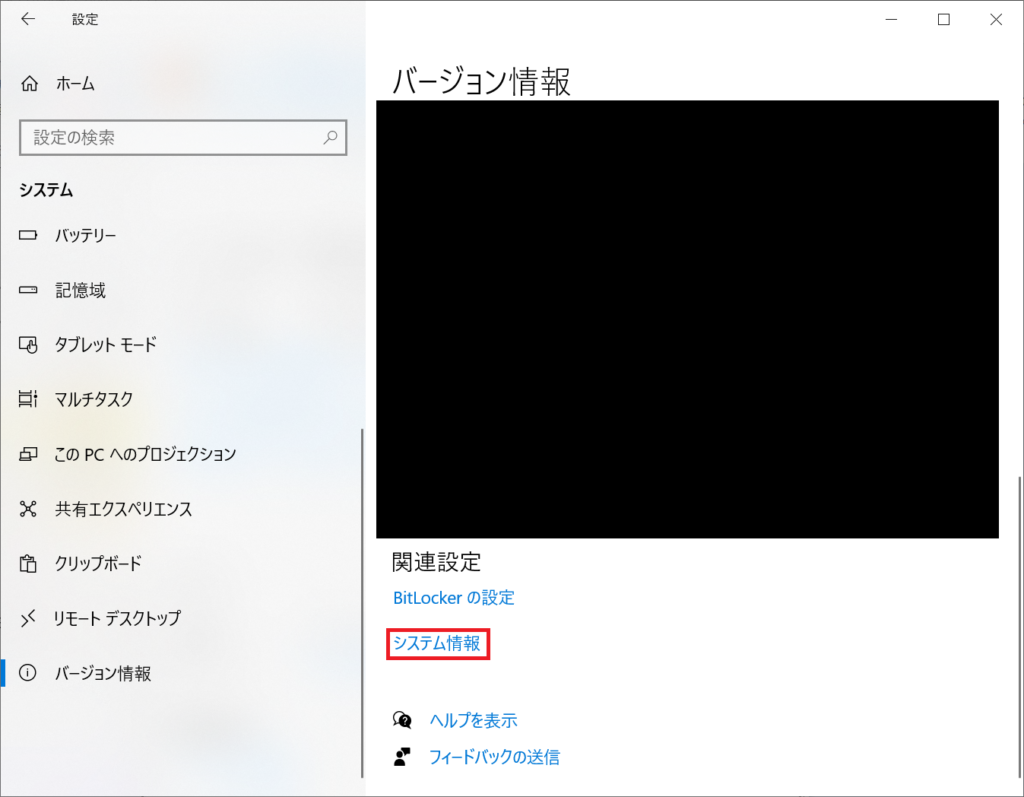
「システムの情報」を開きます。
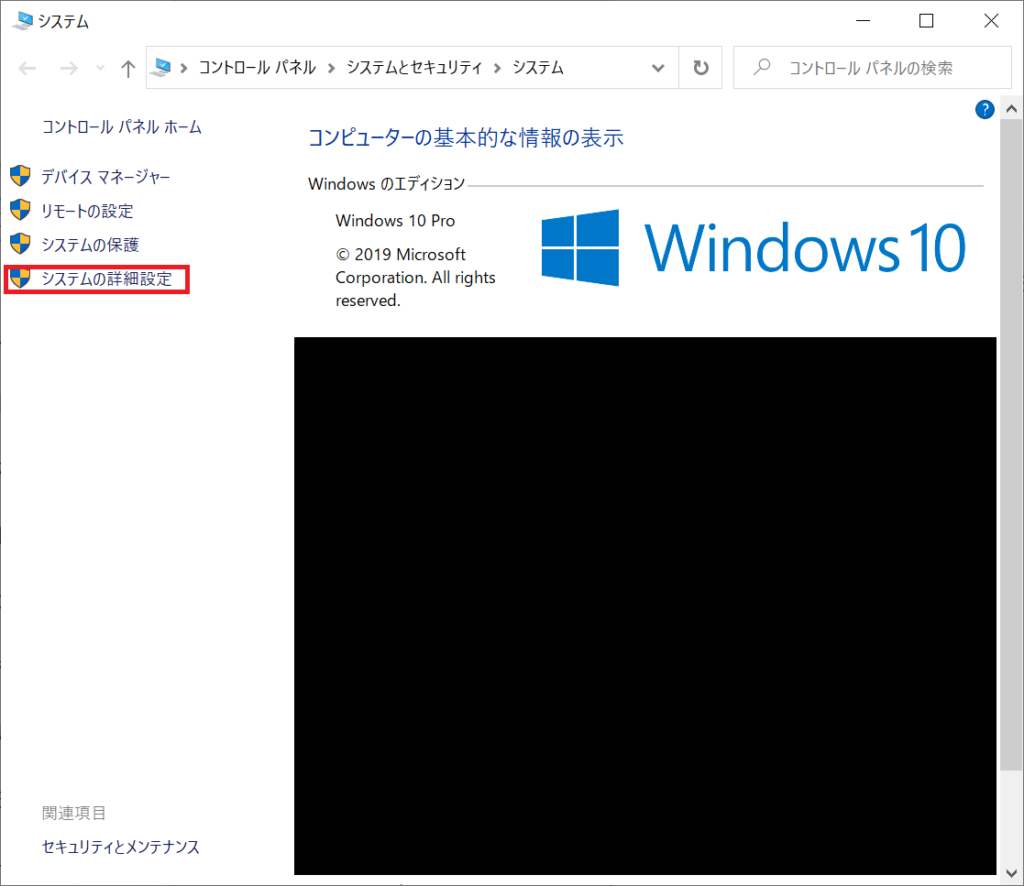
「システムの詳細設定」を開きます。
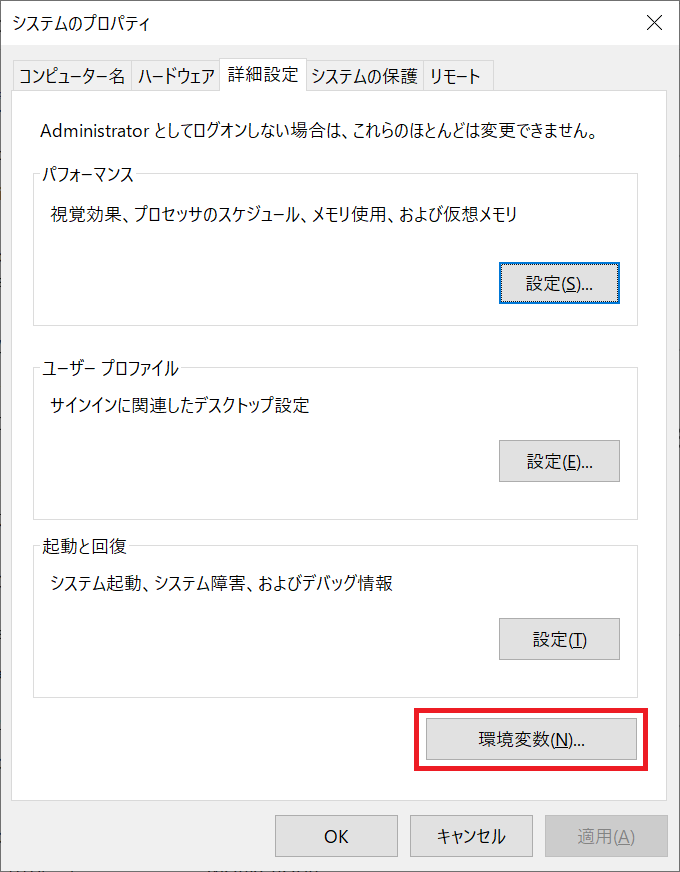
「環境変数」を開きます。
「Path」(または「PATH」)を選んで編集ボタンを押します。
編集画面が出ますので、最後の行に追加したいパスを入力します。
既に入力されている内容を消さないように注意してください。
情報共有ありがとうございます!私も同じ環境と方法でNEologd辞書のインストールまでは問題なくできたのですが、mecab -DでNEologd辞書をちゃんと認識されているにも関わらず、実際には動作せずに困っていましたが、おかげ様で解決しました!辞書を指定するパスにスペースが入っているとダメなんですね。だからLinux環境だと問題ないというのも納得がいきます。それにしても、よく気づきましたね。いろいろ検索しましたが、なかなかこの情報にたどり着けないで迷宮入り寸前でした。たまたま、検索キーワードの1つだったWidowsを間違ってWidowsとタイプしたら、このサイトのタイトルが”WidowsでMeCab+NEologdをインストールする”だったのでヒットして、この情報を見つけることができました。他にも助かった人はたくさんいると思います。本当に感謝です!
コメントありがとうございます。
言われるまで”Widows”になっていることに気が付きませんでした・・・
タイトル修正しておきます。
私もかなり苦戦して諦めかけましたが、コンソール上(mecab単体)では正常に動作していたので、mecabに辞書データを渡す処理で何かおかしいことが起きているんだろうと当たりを付けました。
お役に立ったのなら良かったです
大変に詳細な解説をありがとうございました。PythonでMeCabを使うのはとても難しいようで、方々のサイトの情報を参考にさせて頂きましたが、このページの情報により初めてエラーなく正常に動作するようになりました。しかし、残念ながらNEologd辞書が反映されず、「機械学習」が「機械」と「学習」に分かれる結果となっています。
以下に使用状況をご説明しますので、ポイントが何か、お教え頂ければ幸いです。
ご多忙のところ大変恐縮ですが、宜しくお願いします。
Pythonでは、(バージョン3.7と3.8で動かしてみましたが、同じ結果でした)
import MeCab
m=MeCab.Tagger(“-r C:\ProgramData\MeCab\etc\mecabrc-u”)
とし、
etc¥mecabrc-u ファイル内記述(最後の2行)は、
; dicdir = C:\ProgramData\MeCab\dic\ipadic-UTF8
; userdic = C:\ProgramData\MeCab\dic\NEologd\Neologd.20200910-u
PATHの設定は、C:\ProgramData\MeCab\etc\ です。
返信が大変遅くなってしまい、すみません。
あまり活動自体出来ていなかったのと、すごい勢いで来る英語のスパムコメントに嫌気がさしてコメントチェックしていませんでした。
さて、環境についてですが、私の環境ではPATHはMeCab\binとなっています。
ただ、これに関してはMecabを実行するためのPATHを通しているだけなので、import Mecabでエラーが出ないのであれば問題ないと思います。
原因として思い当たるのはコメントに書き込んでいただいている行頭にある;(セミコロン)です。
私もMecabというパッケージについて詳しいわけではないですが、この;はおそらくコメントアウトの意味だと思います。
現状辞書の読み先を書いたファイルを指定していますが、その中身が空っぽという状態ではないかと推測されますので、そちらの二行のセミコロンは削除してみてください。
> ふたつめのスペースは割と深刻で、私には解決策がわかりませんでした。
環境変数「MECABRC」を設定する方法では、スペースが有っても大丈夫なようです
参考
https://qiita.com/fu23/items/34f55f0b7aaa7e2205b8
https://vasteelab.com/2019/01/03/2019-01-03-170728/