前回までの記事でPythonの実行環境とKerasのインストール方法を紹介しました。
今回はKerasを実際に使用して簡単なネットワークを作成する方法を紹介します。
ニューラルネットワークの構成
これまでのおさらいの意味も含めて、ニューラルネットワークの構成について少し説明します。
ニューラルネットワークは脳の働きを模擬して考案されたニューロンと呼ばれる要素で構成されています。
ニューロンは別のニューロンから接続された複数の入力と、ある一つの値を別のニューロンに出力する複数の出力を持ちます。
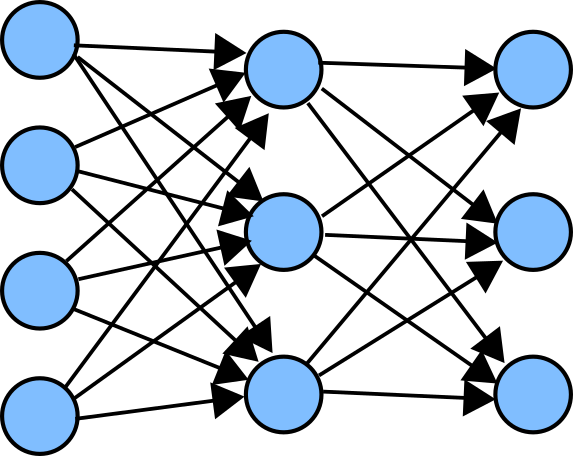
図中の青い丸がニューロンを表し、矢印がニューロン間の接続(出力)を表しています。
ニューロンへの入力結合(接続)にはそれぞれ重みパラメータが設定されており、入力の重み付き和としてニューロンへの入力が計算されるのが一般的です。
この重みパラメータの値は可変で、この重みパラメータを最適化していくことが学習となります。
ニューロンの出力は上記の重み付き和を一度活性化関数と呼ばれる関数に入力した結果とする場合が多く、この関数は非線形関数であることが望ましいと考えられています。
これは入力が線形和(厳密にはバイアス項があるので線形和ではないです)であり、活性化関数が線形であると、出力も入力の線形変換としてしか出力されず、モデルの表現力が限定されてしまうためです。
極端な話をすれば、線形変換を複数回行うことはある一つの線形変換で置き換えられるので、数十層のモデルを作っても1層のモデルと同等の性能しか発揮できないということになります。
(パラメータ数が増えるので過学習が起きやすくなり、むしろ学習性能は悪くなります。)
また、ニューロンはいくつかの層を形成し、同じ層間では接続がないのが一般的です。(図中の各列が各層を表しています。)
図に示されているのは各層間で前層のすべてのニューロンから次層のすべてのニューロンにそれぞれ接続されている全結合層と呼ばれる結合層です。
ニューロンを層だと言ったり、結合を層だと言ったり、一定していませんが、多くのニューラルネットワークモデルを扱うライブラリでは、
・ニューロン
・ニューロンに対して前の層の出力をどう接続(結合)するか
(重みパラメータ含む)
・ニューロンが何を出力するか
をまとめたものを層として扱っているようです。
ニューロンは入力に対してある1つの値を出力し、それを複数のニューロンに接続するかどうかは次層の構成次第ということになります。
一般的に使用されるニューラルネットワーク層
良く使用されるネットワーク層についていくつか紹介します。
- 全結合層 (layer名:Dense)
- 畳み込み層 (layer名:Conv2D)
- バッチ正規化層 (layer名:BatchNormalization)
- Dropout層 (layer名:Dropout)
- Maxpooling層 (layer名:MaxPooling2D)
- Lambda層 (layer名:Lambda)
また、使用するライブラリやAPIによっては活性化関数を層として実装する場合があります。
- ReLU
- Softmax
- tanh
各層の説明については以前の記事を参照してください。
Lambda層については説明していませんが、これは任意の簡単な計算を指定することができる層です。(例えばすべての出力に定数を加算する、2つの層の出力を加算する、出力テンソルの形状を変更する、などです。)
有名な(性能の良い)モジュールもこれらの層を上手く組み合わせて構成されているものが多いです。
これ以外にもネットワーク層については存在し、特に自然言語処理の分野では特殊な層が使用される場合が多いようですが、そちらの分野にはあまり詳しくないのでここでは触れません。
Kerasによるネットワーク構築方法
その1.Sequential モデルAPIを使用する方法
Kerasには大きく分けて2種類のネットワークモデル構築方法が用意されています。
そのひとつ目がSequential モデルAPIです。その名の通り、Sequentialモデルを使用してネットワークを構築します。
Sequentialモデルは与えられた層を順番に結合していくネットワークを作成してくれます。
例えば以下のような使い方をします。
#プログラムの抜粋なので動作しません。
import from keras.models import Sequential
from keras.layers import Conv2D,Activation,MaxPooling2D
model = Sequential()
model.add(Conv2D(16,(3,3),input_shape = (28,28,1)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2,2)))上記のプログラムでは活性化関数”ReLU”を層として追加していますが、Conv2Dには活性化関数を指定する機能もあるので
#プログラムの抜粋なので動作しません。
import from keras.models import Sequential
from keras.layers import Conv2D,MaxPooling2D
model = Sequential()
model.add(Conv2D(16,(3,3),input_shape = (28,28,1),activation = "relu"))
model.add(MaxPooling2D(pool_size = (2,2)))と記述することもできます。
バッチ正規化層などは活性化関数の前に使用するのが良いとされているようですので、バッチ正規化層を使用する場合は活性化関数を別にして最初の書き方でネットワークを構築するのが良いでしょう。
Sequential モデルAPIはネットワーク中に分岐等のないモデルを作成するのに適しています。
その2.Functional APIを使用する方法
もう1つの方法がFunctional APIを使用する方法です。
Sequential モデルAPIが連続して分岐のないモデルを作成するのに適しているのに対し、Functional APIでは分岐等を持つモデルを作成するのに適しています。
Functional APIでは各層の入力となる層を指定してネットワークを作成します。
これを利用して複数の層から入力をしたり、層の出力を複数の層に入力したりすることができます。
Functional APIを用いて上と同じプログラムを書くと以下のようになります。
#プログラムの抜粋なので動作しません。
from keras.models import Model
from keras.layers import Conv2D,MaxPooling2D
inputs = Input(shape=(784,))
#入力:28×28=784要素のベクトル
x = Conv2D(16,(3,3),input_shape = (28,28,1),activation = "relu")(inputs)
x = MaxPooling2D(pool_size = (2,2))(x)
model = Model(inputs = inputs, outputs = x)上記のプログラムではSequential モデルAPIのときと同じように層を作成していますが、作成した層クラスの右側に更に(x)をつけて入力としてxを指定しています。
最後にモデルのインプットとアウトプットを指定してネットワークモデルを作成しています。
実装例:手書き数字認識(MNIST)
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation,MaxPooling2D,Conv2D,Flatten
from keras.optimizers import Adam
from keras.utils import np_utils
import time
import numpy as np
import os
#モデルを作成する関数
def build_model():
model = Sequential()
model.add(Conv2D(16,(3,3),input_shape = (28,28,1)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Conv2D(32,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])
return model
#ここから実際に実行
if __name__ == "__main__":
#学習用データの読み込みと下準備(MNIST:手書きデータ)
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(60000, 28,28,1).astype('float32')
X_test = X_test.reshape(10000, 28,28,1).astype('float32')
X_train /= 255
X_test /= 255
y_train = np_utils.to_categorical(y_train, 10)
y_test = np_utils.to_categorical(y_test, 10)
#モデルを作成、モデルの内容を表示させる。
model = build_model()
model.summary()
#学習を実行
time_start = time.time()
model.fit(X_train, y_train,batch_size=128,epochs=20,
validation_data=(X_test, y_test)
)
#(学習にかかった時間を表示)
time_end = time.time()
print("time:",(time_end - time_start))
# モデルの評価を行う
score = model.evaluate(X_test, y_test, verbose=1)
print('loss=', score[0])
print('accuracy=', score[1])以前にも掲載した手書き数字認識のプログラムソースコードです。
簡単に内容について説明していきます。
1.必要なライブラリのimport
mnist:手書き数字の有名なデータセット。
このデータを使用する機能がKerasには標準で用意されています。
Sequential:KerasのSequential モデルAPIを使用するためのモデル
Dense, Dropout, Activation,MaxPooling2D,Conv2D,Flatten:
Kerasの各層を実装するための層モデル
(Flattenは2次元以上のベクトルを1次元のベクトルに変換する層)
Adam:最適化手法Adamを使用するためのモデル
np_utils:Kerasに用意されている便利機能がまとめられたモジュール
time:時間に関するモジュール。計算にかかった時間を計測する。
numpy:数値計算用のライブラリ
os:ファイル操作等、OSに関わる機能がまとまったモジュール。
今回は使用していないが、学習内容を記録する際などに使用する。
2.モデル作成用の関数 build_model()
モデルを再利用する場合などがあるため、モデル作成は関数にしておく。
例えば学習と、それを使用した予測を別のプログラムで行いたい場合など、モデル作成を関数として切り分けておくと便利な場合が多い。
今回使用するネットワークの概略は以下の通り。
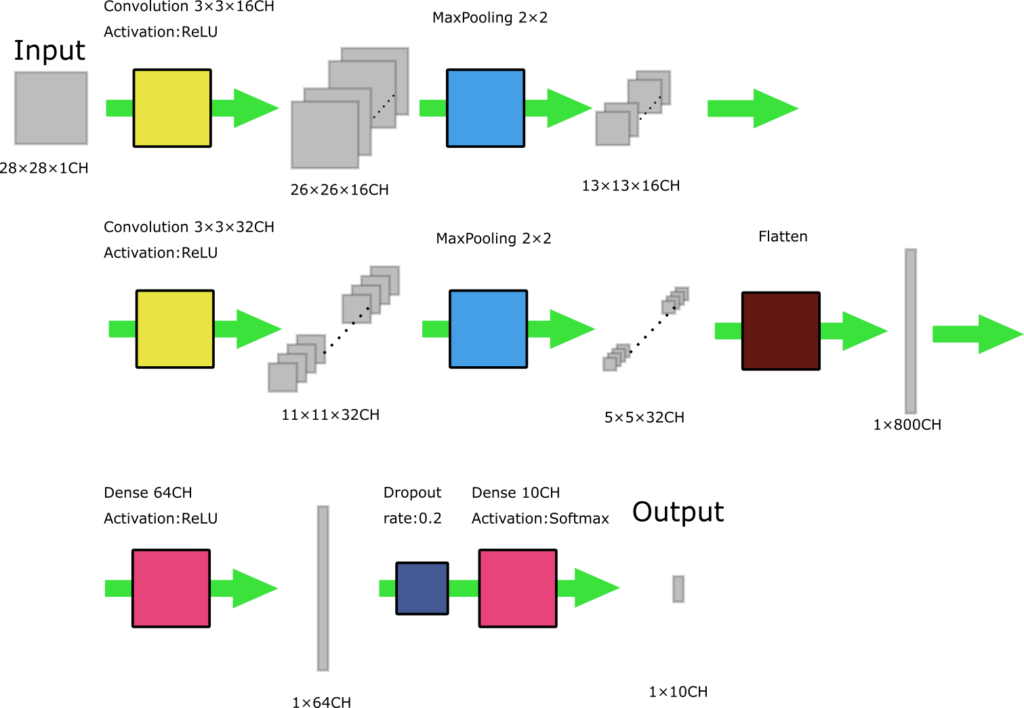
畳み込み層とMaxPoolingのセットを2回、その後全結合層により64chのベクトルとし、出力を作る10ch(数字0~9に対応する)との結合間にDropout層を挟んでいます。
最後の全結合層の活性化関数にはSoftmax関数(シグモイド関数の3クラス以上版)を使用し、0~9に対応するベクトルの総和が1となるようにしています。
これにより各ベクトル要素の値はそのまま該当クラスである確率を示すようになります。
また、図中にもある通り畳み込み層はpaddingを指定していないので元の行列よりもサイズが少し小さくなっています。MaxPoolingは2×2の範囲の最大値を拾いますが、余り分は反映し仕様となっているようです。
最初のインプットを受け取る畳み込み層のみinput_shapeを指定していますが、他の層については前後のつながりから適切な接続を行ってくれます。
モデルの接続が終わったら計算用にコンパイルします。
#抜粋
model.compile(
loss='categorical_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])コンパイル時には損失loss、最適化手法optimizerを指定します。
任意でmetricsを指定すると指定した値を監視することができます。
(今回の例では予測精度(“accuracy”)を指定しています。)
lossに指定されている”categorical_crossentropy”は分類用のクロスエントロピーです。二値分類用の”binary_crossentropy”というものもありますが、このクロスエントロピーとは対数尤度にマイナスを掛けたものです。
尤度とは尤もらしさ(もっともらしさ)を示すもので、ある分類モデル(今回で言えばニューラルネットワーク)が確率的に分類されるクラスを表現したときに(例えばAである確率40%、Bである確率60%)、xがあるクラス(正解クラス)に分類される確率を表したものです。
集合Xに対しては、すべての要素xの同時確率なので、それぞれの尤度の積となります。対数を取ると積は和になり、扱いやすくなるので対数尤度を用います。
また、尤度は尤もらしさを表すため、正解クラスに分類されるほど値が大きくなります。一般に最適化問題などでは損失を最小化することが多いので、マイナスを掛けることで最小化問題として扱います。
最適化手法はそのまま、最適化を行う手法のことです。
ニューラルネットワークでは誤差逆伝播により学習するべき誤差が求まりますが、これは「現時点」のパラメータ空間上の位置から、最も誤差が減少する「方向」を示しています。
パラメータ空間上での誤差関数は決して平たんではなく、うねった曲面を形成しています。現時点からはその方向が最良と思われるかもしれませんが、少しその方向に進めば、実は最良となる方向は変化しているかもしれません。
また、方向は分かっていても距離は分かりませんので、例えば最適な位置がすぐ近くであれば行き過ぎてしまうような場合もあります。逆にパラメータの更新量が小さすぎると、最適位置がとても遠くていつまでもたどり着かないという場合も考えられます。
このような問題を解決するため、様々な最適化手法が提案されています。
私も内容についてはあまり詳しくないですが、Adamが使われることが多いようですので、特に理由がなければAdamを使用しておけば良いと思います。
3.MNISTデータのロード
MNISTのデータをロードします。
#抜粋
(X_train, y_train), (X_test, y_test) = mnist.load_data()戻り値は書いてある通り訓練用データと訓練用データのラベル(0~9)のセット(60,000組)、評価用のデータと評価用データのラベル(0~9)のセット(10,000組)です。
データは白黒で整形されていません。reshapeを使用して60,000個の28×28×1行列に整形します。(testも同様)
データは単純な正規化として255.0で割って0.0~1.0の間にします。
ラベルデータは0~9の値が入っていますが、カテゴリカルクロスエントロピーを使用するためにはone-hot形式のベクトルが必要となるので、np_utilsのto_categorical機能を使って変換します。
one-hot形式とは、例えば全部0~9の10クラスに分類出来て、「9」であれば
(0,0,0,0,0,0,0,0,0,1)
という風に該当するクラスインデックス部分だけが1、あとは0という表現方法のことです。
4.学習
モデル作成用の関数は上で作成しましたので、これを使ってモデルを作成します。
作成したモデルでsummary()を呼び出すとモデルの概略が見られます。
上で示した各層の出力の他に、各層のパラメータの数なども確認できます。
自分が作成したモデルが意図した通りになっているかを確認するのに便利な機能です。
学習を実行するための関数はいくつか用意されているようですが、今回は一番簡単なfitを使用しています。
#抜粋
model.fit(X_train, y_train,batch_size=128,epoch=20,
validation_data=(X_test, y_test)
)fitで使用している引数は以下の通りです。
X_train(第1引数):学習に使用するデータ
y_train(第2引数):ネットワークが出力するべきデータ
batch_size(第3引数):バッチサイズ。一度に学習するデータ数
epoch:エポック数。バッチサイズ毎に学習を行い、与えられた
学習用データすべてについて学習が終了したら1 epoch
validation_data:評価用データ。訓練に使用していないデータで性能を確認
することでモデルが過学習状態になっていないか確認する。
これ以外にも指定可能なパラメータがいくつかあります。詳しくはKerasのドキュメントを確認してください。
fitの前後にtime()を使用して時間を記録しています。秒単位(小数なので分解能はさらに細かいです)で記録されるようなので、差を取ることで学習にかかった時間が分かります。
5.学習したモデルの評価・予測
evalを使用して学習したモデルの予測精度を評価します。
#抜粋
score = model.evaluate(X_test, y_test, verbose=1)
print('loss=', score[0])
print('accuracy=', score[1])今回は評価用データを使用して、その結果を表示させています。
コンパイル時のmetricsに”accuracy”を指定しているのでscore[1]にはaccuracyが保存されています。
正解ラベルを持たないデータで予測を行う場合にはpredict関数を使用します。
#プログラムの抜粋なので動作しません
pred = model.predict(x)
#戻り値はone-hot形式に対応した各クラスに属する確率(0~1)
y = numpy.argmax(pred)
#最大となる要素のindexを取得確率が最大のものを予測結果としても良いですし、用途によってはある一定の確率を超えるものがない場合は該当なしとするなど、様々な利用方法があります。
このプログラムで学習済みのモデルを読み込んで、入力された画像について計算しているのが下記のデモページになります。
以上が、簡単ですがKerasによる深層学習の実装方法になります。
今回紹介した手書き数字認識は、画像処理について専門的な知識を持たない人でも簡単に実装できるという意味でとても素晴らしい技術だと思います。
しかし、今回でいえば認識できる数字は0~9のみで、枠に収まっていなければ認識の精度が低くなるため、すぐに有効活用できそうな場面を思いつくのはなかなか難しいです。
例えば郵便局では郵便物に書かれた文字を基に、配達先の分類に利用できるかもしれません。
もちろん、今回紹介した手法は初歩の初歩ですので、2桁、3桁の数字に対応されていったり、数字以外の文字を認識できるようにしたり、画像全体から数字や文字を見つけ出すようにネットワークを拡張していくこともできます。
ただし、それにはそれぞれに合ったネットワークを模索していく必要があります。
今回紹介したように、深層学習の実装はとても簡単で、様々な分野に応用されています。
しかし、実際には深層学習自体はただの手法ですので、それだけで夢のような結果が得られるわけではありません。
深層学習に関しては多くの素晴らしい手法(お手本)が世の中に出回っています。
この素晴らしい技術をどのように利用していくかを考えることが、深層学習を利用する上で重要になってくると思います。
(私もそれは見つけられていません。)
次回以降は、単発で深層学習に関わるトピックスをいくつか書いていこうと思います。