深層学習を実際に行っていくための環境構築について説明します。
最初に私の使用している環境ですが
OS:Windows10
プログラミング言語:python
python実行用環境:Anaconda(Jupyter Notebook)
となっています。
深層学習は学習手法ですので、プログラミングが可能であれば特定の言語や環境でなければ出来ないというわけではありません。
しかし、実際にはほとんどの人がプログラミング言語としてpython(パイソン)を使用しているというのが実状です。
私も以前はプログラミング言語としてJavaを使用しており、それ以外の言語については簡単に触れたことがある程度でしたが、機械学習を勉強するにあたり、pythonも使えるように多少勉強しました。
深層学習を実際に行う際にはpythonを使用することを強くお勧めしますし、今後の説明はpythonの使用を前提として進めていきます。
なぜpythonを使用するのが良いのかについて少し説明します。
pythonの特徴・使用する利点
pythonはプログラム開発者の労力を減らし、コードを極力簡潔にするという考えを基に作られています。
pythonの特徴
pythonはインタプリタ型の言語で、コンパイルして実行用ファイルを作成するという作業がありません。
また、変数の宣言時に型名を宣言しません。
この辺りはJavaやC++などを使用している方には少し馴染まない部分かなと思います。Javascriptなどを使用している人は逆に馴染みやすいかもしれません。
コンパイルを行わないのでエラーは実行時に判明します。
計算終了後、保存用のコードが間違っていたため計算し直しなどという場面も割とあります。
また、型名を明示していないため、思わぬ動作をする場合があります。
特に数値演算で行列を扱うことが多く、行列の次元が想定と違う、行列の種類が想定と違うなどの場合ではエラーとなりますが、これも実行するまで分かりません。
この辺りはJavaではきっちりとしており、コンパイル時にエラーとして通知されていたので私が良く躓いた部分です。
他の言語から入ったということで、少しネガティブな部分を押し出してしまいましたが、もちろん良い部分もたくさんあります。
pythonを使用する利点
最初にも述べましたが、python言語はプログラム開発の労力を減らすように設計されています。
特に行列やリスト周りの操作はとても楽です。
数値計算は特性上行列やデータの集合(リスト)を扱う場合が多く、これらの操作が簡単に行えるというのは、大きな利点だと思います。
例としてある行列の2行2列から8行7列までのデータを取り出した行列を作る場合を考えます。
Javaの場合
a; //元の行列 すでに数値が入っているものとします。
int ROW_START = 2,ROW_END = 8,COL_START = 2,COL_END = 7;
//取り出す行列の始まりと終わりの行、列
double b[][] = new double[ROW_END- ROW_START + 1][COL_END - COL_START + 1];
//配列の初期化
for(int i = 0;i < b.length;i++){
for(int j = 0;j < b[i].length;j++){
b[i][j] = a[i + ROW_START][j + COL_START];
}
}これで変数bが表す配列に元の行列(配列)aの値がコピーされました。内容としては範囲を指定して各行、各列について値をコピーしています。
これに対してpythonでは
import numpy as np
a #元の行列(numpy.ndarray型) すでに数値が入っているものとします。
ROW_START = 2
ROW_END = 8
COL_START = 2
COL_END = 7
//取り出す行列の始まりと終わりの行、列
b = a[ROW_START:ROW_END + 1][COL_START:COL_END + 1].copy()
定数の宣言を各行に分けて長く見えますが、実質的には1行で終わっています。
なぜこのようになるかというと、一つはnumpyという行列を扱うのにとても便利なライブラリがあること、もう一つは言語として「スライス」と呼ばれる機能を実装していることです。
スライスは、行列やリストなどの添え字に[start:end]のような形で書くことで、その行列やリストのstart番目から(end-1)番目までの要素を示す行列やリストとして扱うことができるという機能です。
また、numpyによる行列の計算として
import numpy as np
a = np.array([1,2,3,4]) #中身が[1,2,3,4]のndarray
b = a + 4
print(b)
#bは中身が[5,6,7,8]のndarrayのように行列に対してスカラーを加算する演算などを”+”演算子で行ってくれます。減算、乗算、除算なども同様です。
Javaでは難しいですが、C++などには演算子のオーバーライド機能などもあるようですので、このようなことは可能です。
javaにしてもこのようなメソッドを作成しておけば1行で実行すること自体は可能です。
ただ、プログラム開発を行っていくと、このような小さな手間がどんどん積み重なっていきます。
このような手間を減らせるというのは実は大きな利点だと思います。
このように言語的に特徴があり、使いやすい部分は色々あるのですが、
何よりも大きなpythonを使用する利点はpythonの周辺環境が整っていることだと思います。
周辺環境というのは使用可能なライブラリの種類もそうですが、実際数値計算等の分野で使用している人の数が多いということです。
使用している人の数が多いというのは実はとても重要で、例えばGoogleが制作している深層学習用のライブラリであるTensorflowでは、最新の研究で成果が得られたモデル・機能等を日々追加されています。
これはTensorflowが広く研究者に使用されているからで(Google自身もこの分野の研究の第一人者です)、これがJavaのライブラリを使用する場合、機能が追加されるまでしばらく待つか、自分で1から実装しなければなりません。
もし機能が追加されなくても、研究者がコードを公開してくれていればそれをそのまま使用して実際に試してみることも可能でしょう。
このような点から深層学習の分野ではpythonとその周辺ライブラリがとても多く使用され、さらにそれが新たなpython使用者を呼ぶこととなっています。
結論:pythonを使用しましょう。
python実行環境の構築
最初にも書きましたが、私は実行環境のOSとしてWindowsを使用しています。
ただ、世の中的には深層学習等の環境を構築する際にはLinuxベースOSである”Ubuntu”を使用する場合が多いようです。
実際、Ubuntuにしか対応していない深層学習ライブラリ等もあり、それが使用できないということは、前に述べたようにそのライブラリを使用している研究者の成果をすぐには流用できないということになります。
また、使用者が多いということは実例も多く、フォーラム等でトラブル時の解決方法を教えてもらえる場合も多くなります。
あるフォーラムではライブラリの開発者が「私はWindowsのことはよく分からないですが・・・」というような発言をしているのも見かけました。(実際は英語でした)
私自身Windowsを使用しているために要らない苦労をする場面も多かったです。
特にフォルダ名に全角文字やスペースを使用するのはトラブルの元になる場合が多いのでWindowsを使用する場合でもこれは極力避けましょう。
(Windowsの”Program Files”やGoogleの”Colab Notebooks”に何度イライラさせられたか・・・)
まとめると、ローカルで深層学習を行う環境としてはUbuntuがお勧めですが、一応下記のような方法があります。
1.Ubuntuを使用する。(お勧め)
2.Windowsを使用する。
2-1.Windows上でpythonを使用する。
2-2.Windows上でUbuntuの仮想環境を構築する。
3.MacOSを使用する。
4.クラウドサービスを利用する。(お勧め)
Ubuntuの使用をお勧めしていますが、私は2-1以外の方法をほとんどやったことがありません。
基本的には2-1.のやりかたを説明していきますが、環境が構築できればその後の内容については大きな差はないはずです。
4.のクラウドサービス(特にGoogle Colaboratory)についてはまたの機会に紹介したいと思います。
Windows上でpython実行環境を構築する
(Anaconda)
調べるとWindows用のpythonもあるようなので、そちらをインストールしてもよいのですが、多くの数値計算関係の書籍等でAnacondaがお勧めされています。
AnacondaはPython派生の一つで、基本的なPythonの機能に加えて便利な各種機能が追加されたものです。numpy等の数値計算では必須となるライブラリなどは標準で付属しているようです。(numpyをインストールした記憶が最早定かではない・・・)
また、実行環境として比較的人気のあるものの一つである”Jupyter Notebook”もついてきます。
Jupyter Notebookはブラウザ上で動作するpython実行環境です。
私は普段こちらを使用してpythonのプログラムを作成しています。
実際の実行画面は下のようになります。
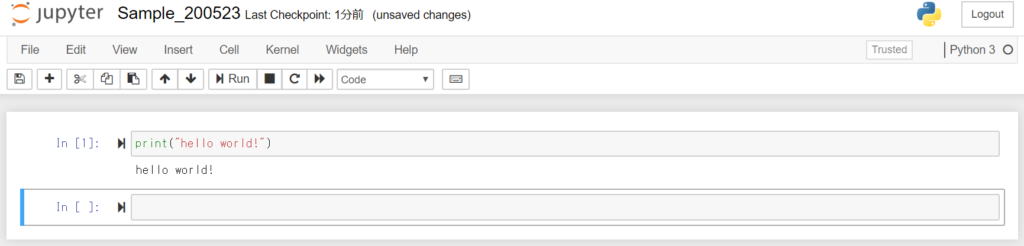
pythonはコードを読み込みながら実行していく言語ですので、ブラウザ上にコードを記入し、それをブロック毎に実行していくことができます。
同じことはpythonのインタラクティブシェルを使用することでも可能ですが、こちらはPowerShellやコマンドプロンプト上で動作するので入力内容は保存されません。
Jupyter Notebookの欠点として、保存されるファイル形式がipynbなので、そのままでは他のpythonプログラムで流用したいときにimportすることができません。
併せて通常のエディタまたは統合開発環境を使用して.pyファイルを編集することをお勧めします。
pythonのエディタや統合開発環境で有名なものがいくつかあるようです。
- Atom
- PyCharm
- Visual Studio Code
私はAnacondaに付いてきたVisual Studio Codeを使用していますが、Atomなどのほうが良く使われるようです。(現在のAnaconda インストーラにはVisual Studio Codeは付いてこないようです。)
他のものは使ったことがないので特にお勧めはできませんが、気に入ったものを使えばよいと思います。
Anacondaのインストール
Anacondaは下記のサイトからダウンロードできます。
https://www.anaconda.com/products/individual
各OS、各pythonのバージョンによってインストーラが異なります。
python2系は2020年でサポート終了となるようなので、基本的にはpython3系をお勧めします。(2→3となる際に大幅な変更があり、互換がない部分があるらしく、一部ユーザーがpython2を使用し続けているようです。)
注意点として、下記画面で”Just Me”(このユーザーのみ)を選択しましょう。
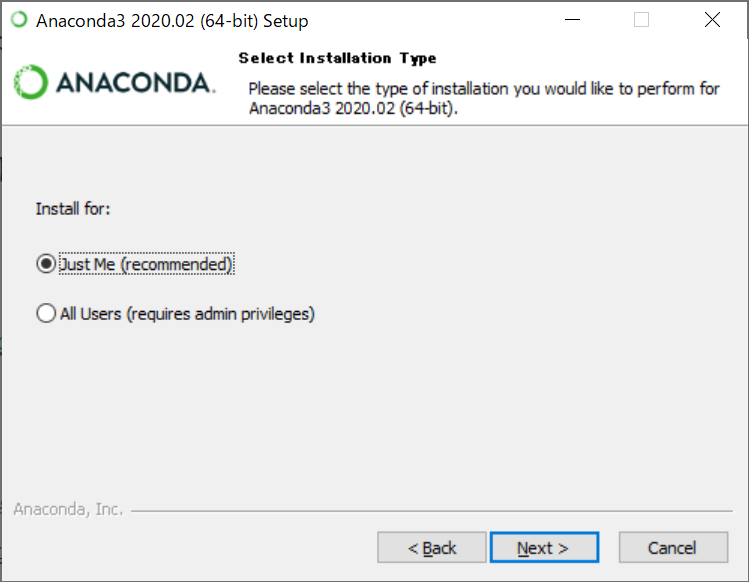
“All Users”を選択すると、インストール自体は可能ですが、その後pythonライブラリをインストールする際に書き込み権限を得られず上手く動作しない場合があります。
“Just Me”を選ぶとユーザー名が英数字でない場合アラートが出ると思うので、適切なフォルダを指定してください。
このとき、前述した通りフォルダ名にスペースが含まれる場所は避けることをお勧めします。
Anacondaで仮想環境を構築する
インストールが終わったら、仮想環境を構築しましょう。
仮想環境は構築しなくてもpythonを実行することができますが、仮想環境を構築することをお勧めします。
理由として、pythonの各ライブラリは別のライブラリの機能を利用して作成されているケースがとても多いです。
特に数値計算に用いる場合には似たような機能が多いので、使用しているライブラリも重複している場合が多いです。
これらのライブラリが同じバージョンに基づいて作成されていればよいですが、バージョンアップなどにより互換がない、もしくは動作時にバージョンチェックで弾かれるなどの理由で各ライブラリが正常に動作しない場合があります。
仮想環境を構築する方法もいくつかあります。
- conda (Anacondaの機能)
- virtualenv
- venv(python3.4以降の標準機能)
こちらも好きなものを使用すればよいと思いますが、今回はインストールしたAnacondaの機能を使用して仮想環境を構築する方法を紹介します。
condaによる仮想環境の構築方法
(その1 PowerShell上で構築操作をする)
AnacondaをインストールしただけではcondaやpythonにはPathが通っていないようですので、condaを使用する際にはPATHを通してコマンドプロンプト上で操作するか、conda付属のPowerShellまたはAnacondaPromptを使用します。
PowerShellとAnacondaPromptは、Windowsであればスタートメニューのプログラム一覧内にAnacondaの項目があるはずですので、その中から起動してください。
PowerShellとAnacondaPromptは正確には違うもののようですが、私にはその差が分かりません。どちらかというとAnacondaPromptのほうが使いやすいのでそちらを使用しています。
(例:仮想環境の有効化時のコマンドが
PowerShell :conda activate ○○
AnacondaPrompt :activate ○○
等、微妙に違いがあります。
実際にはPowerShellのほうが高機能のようです)
以下はAnacondaPromptでの説明となります。PowerShellを使用したい方は適宜コマンドを読み替えてください。
プロンプト上で下記の通りコマンドを打ち込み、新しい環境を作成します。
(test_envは環境名なので自由に名付けてください。)
conda create -n test_env進めますか?(Proceed?([y]/n))と聞かれるので”y”を押して環境を作成します。
作成が完了したら以下のコマンドをプロンプトに打ち込み、環境を有効化します。(test_envは作成した環境名)
activate test_envするとプロンプトのコマンド打ち込み部分に(test_env)と書かれているはずです。(環境有効化前は(base)という共通環境)
この状態でライブラリやパッケージをインストールしたり、アンインストールしても他の環境には影響を与えません。
環境を無効化するにはプロンプトに下記のように打ち込みましょう。
(このときは環境名は要りません。)
conda deactivate
condaによる仮想環境の構築方法
(その2 Anaconda Navigatorで環境を構築する。)
Windowsであれば、スタートメニュー⇒プログラム一覧⇒Anaconda内に”Anaconda Navigator”があるはずです。
これはAnacondaの各種機能をまとめたGUIで、こちらからも仮想環境を構築することができます。

左側にある”Environments”のタブをクリックすると環境管理画面になります。
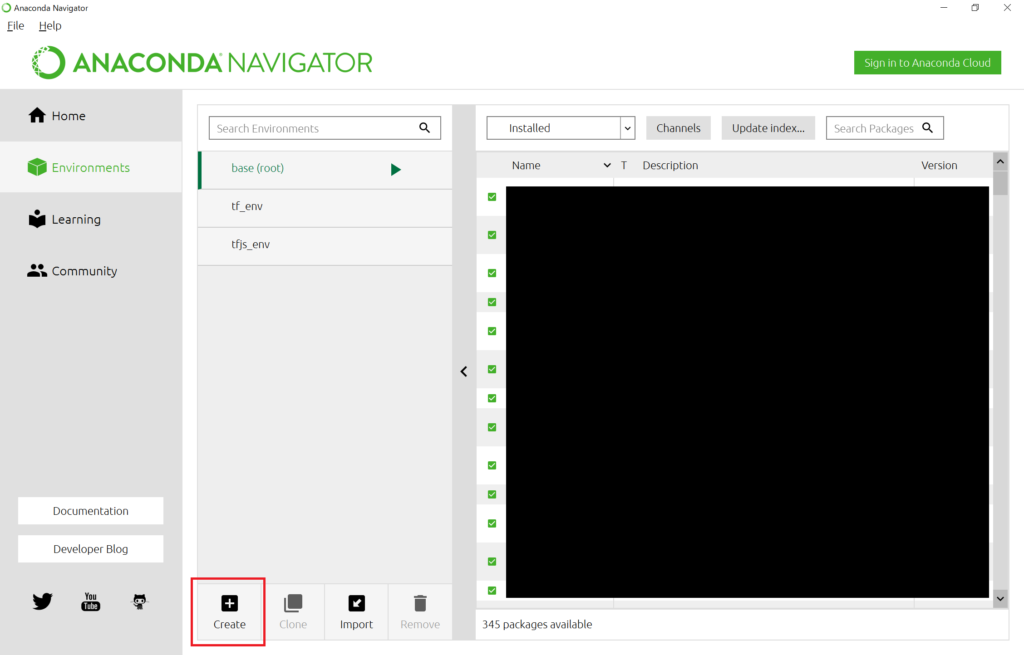
右側にはその環境でインストールされているパッケージの一覧が表示されます。
下の方にある”Create”ボタンを押すことで新しい仮想環境を作成することができます。
使用するpythonのバージョンを選択し、名前を入力して”Create”を押せば環境が作成されます。
使用方法は上記の場合と同じくプロンプトを使用します。
Jupyter Notebookを使用する
Jupyter NotebookはWindowsであればこれまで同様にスタートメニュー⇒プログラム一覧⇒Anaconda内にあります。
ただし、このショートカットから起動したJupyter Notebookは共通環境(base)を基に起動されます。
仮想環境を基にJupyter Notebookを起動するにはAnaconda NavigatorのHome画面で環境を切り替え(base(root) ⇒ test_env)、Jupyter Notebookの”Launch”ボタンをクリックして起動します。
環境にJupyter Notebookがインストールされていない場合”Launch”ボタンではなく”Install”ボタンが表示されるので、クリックしてインストールしましょう。
ちなみに私の環境ではこの方法ではうまく起動できませんでした。
ホームディレクトリに当たるフォルダ名が全角であることが原因ではないかと考えられます。
Anaconda Navigator を使用しない方法としてはプロンプト画面で環境を有効化し、以下のようにコマンドを打ち込みJupyter Notebookを起動します。
・環境を有効化
activate test_env・Jupyter Notebookをインストール(仮想環境にインストールされてない場合のみ)
conda install jupyter notebook・Jupyter Notebookを起動
jupyter notebook起動するとプロンプト上に
To access the notebook, open this file in a browser:
file:///C:/Users/○○○○.html
Or copy and paste one of these URLs:
http://localhost:○○/?token=○○○○
or http://127.0.0.1:○○/?token=○○○○のような表示が出るので、こちらをブラウザのURL欄にコピーすることでJupyter Notebook が使用できます。
(○○や○○○○の部分は環境や設定により異なります。)
このような手順を毎回行うのは面倒ですので、おまけ2に載せた方法も確認してみてください。
Jupyter Notebookでpythonを実行する
Jupyter Notebookが起動出来たら、適当な場所にpythonコードを保存するフォルダを作成しましょう。
Jupyter Notebook上でもエクスプローラーのようにファイルブラウジングができますのでこちらを使用してもよいと思います。
Jupyter Notebook上で使用するフォルダに移動したら、右側のNewボタンを押して”Python3″ファイルを作成します。
(python2系を使用している場合は表記が異なるかもしれません。)
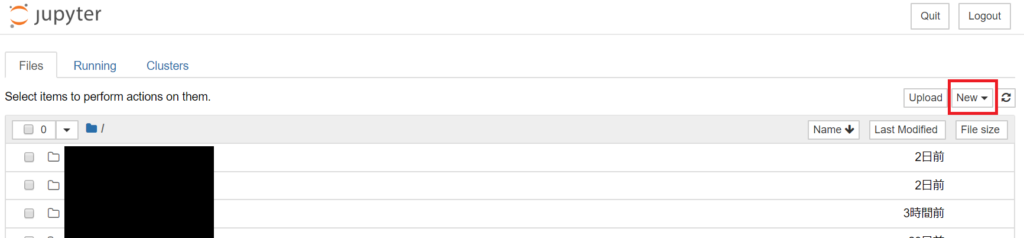
あたらしいファイルが作成され、タブ(もしくはウィンドウ)が開いたら試しにpythonプログラムを打ち込んでみましょう。
print("hello world!")Runボタンをクリックすると選択しているセルの内容が実行されます。
ここまででpythonが実行できるようになりました。
次回以降、深層学習に必要なライブラリのインストールと簡単な使い方について説明していきたいと思います。
おまけ:プロンプト上でpythonを実行する
Visual Studio Code等のコードエディタにはプログラム実行・デバッグ用の機能がついているので必要ないかもしれませんが、プロンプト上でpythonを実行する方法について説明します。
使用する仮想環境を有効化し、
python ○○.pyと打ち込みます。以上です。pythonの部分は環境等によりpython3,python2等でも大丈夫です。Anacondaを使用している場合は単にpythonと打ち込めば上手く処理してくれます。
(○○.pyはコードを書いたファイル名です。拡張子は.pyにしましょう)
ちなみに
pythonとだけ打ち込むと”>>>”という表示が現れ、インタラクティブなプログラム実行が可能です。
(打ち込んだ1行ずつプログラムを実行していけます。)
これを利用して例えば
>>> import tensorflowと打ち込めば”tensorflow”パッケージが正常にインストールされたかどうかなどが分かります。
インストールが上手くいっていない場合などはエラーが表示されます。
(>>>はプロンプト側の表示で、こちらが打ち込む必要はありません。)
インタラクティブなpythonから抜け出す場合には
>>> exit()と打ち込みましょう。
おまけ2:Jupyter Notebook上で環境を切り替えられるようにする
上記の通り仮想環境を切り替えてJupyter Notebookを起動するのは結構手間がかかるので、JupyterNotebook上で環境を切り替えられるようにする方法があります。
1.Jupyter Notebook上で環境を切り替えるためのパッケージをインストールする。
アナコンダプロンプト上で以下のように打ち込みます。(環境はbaseのままです。)
pip install environment_kernels2.Jupyter Notebookの設定ファイルを作成する。
プロンプト上で以下のように打ち込みConfigファイルを作成します。
jupyter notebook --generate-config作成されたファイルの場所が表示されるのでそれをメモ帳やコードエディタ等で編集します。
(普通は”C:\Users\user名.jupyter\jupyter_notebook_config.py”として作成されるようです。user名はPCのユーザー名が入ります)
ファイルの最後に以下の行を追加します。
c.NotebookApp.kernel_spec_manager_class = 'environment_kernels.EnvironmentKernelSpecManager'
c.EnvironmentKernelSpecManager.env_dirs=['環境が作成されたフォルダ']環境が作成されたフォルダは通常ではAnacondaをインストールしたフォルダ内の”/anaconda/envs/”になります。(anacondaフォルダより上の階層は環境により異なるので各自の環境で入力してください。)
バージョンによっては
c.EnvironmentKernelSpecManager.conda_env_dirs = ['環境が作成されたフォルダ']の1行追加のみで行ける場合もあるようです。
3.Jupyter Notebook上で環境を切り替える。
環境を切り替えずにショートカット等からJupyter Notebookを起動し、pythonのコードを書いたファイルを開きます。
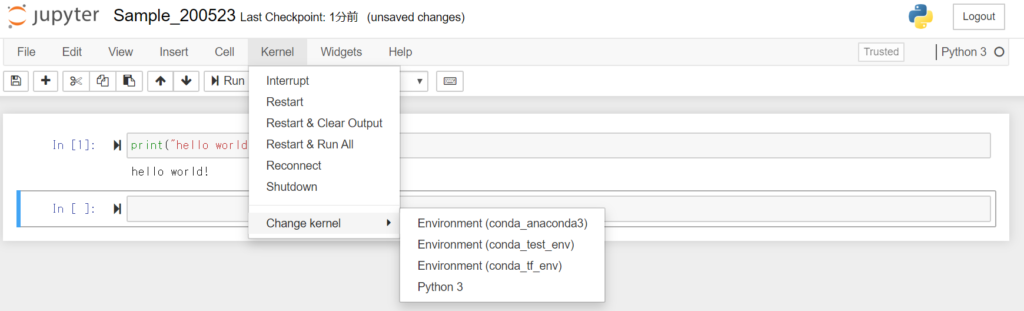
メニューの”Kernel”から”Change kernel”を選ぶと環境を選択できます。
ここで注意点ですが、仮想環境にJupyter Notebookがインストールされていないと自動的に認識されず、この選択項目に表示されないようです。
上に書いた方法でJupyter Notebookをインストールするか、初めから仮想環境にインストールしておくには環境作成時に
conda create -n test_env jupyterという風に打ち込んで環境を作成しましょう。
(test_envは環境名です。)