Google Colaboratoryとは
Google Colaboratory(以下Colab)とは名前の通りGoogleが提供している学習用のPython実行環境クラウドサービスです。
アクセスは以下から可能です。使用にはGoogleアカウントが必要なようです。
https://colab.research.google.com/notebooks/intro.ipynb
Google Colaboratoryの特徴
Google Colaboratoryの特徴としてトップページに以下のように書かれています。
- 構成が不要
- GPU への無料アクセス
- 簡単に共有
ColabではデフォルトでTensorflowやNumPy等の機械学習やデータ解析に使用されるパッケージがインストールされており、以前に紹介したような環境の準備が必要ありません。
画面はJupyterNotebookによく似ており、使用方法もほとんど同じです。
コードを書いたノートブックはGoogleDrive上に保存されるので、ネットに接続できる環境であればどこからでもアクセス可能です。
実行もクラウド上のサーバーで行われるので、スマホからでも機械学習プログラムが実行可能です。
そして私が個人的に一番の利点だと思っているのはGPUマシンが無料で使用可能であるということです。
機械学習のプログラムはGPU環境がほぼ必須と言われていますが、高性能のGPU(グラフィックボード)はそこそこの値段がします。
これが無料で使用できるというのはとてもありがたいです。
しかも、Colabでは更に行列演算に特化したTPU(Tensor Processing Unit)を無料で使用することもできます。
このような理由で、手軽に機械学習に触れてみたいという方にはとてもお勧めな実行環境となっています。
Google Colaboratoryのマイナスポイント
そんな素晴らしいGoogle Colaboratoryですが、マイナスというか、気にしておくべきポイントもあります。
まず、連続使用に制限があります。
- 使用端末との接続が切れると90分でサーバーが停止する。
- 使用開始から12時間連続使用するとサーバーが停止する。
使用端末との接続が切れるというのは、ブラウザやタブを閉じたり、PCやスマホがスリープ状態になったりということです。
(スマホだとブラウザがスリープ状態になる場合も該当すると思います。)
90分制限の方はPC等をスリープ状態にならない設定にしておけば問題ないですが、12時間制限の方については回避する方法はありません。
基本的に深層学習における学習はPC等のメモリ上で行われますので、サーバーが停止するとメモリ上の内容はすべて消えてしまいます。
また、ストレージもサーバーが起動するときに割り当てられるようですので、そちらの中身もおそらく消えます。
12時間以内に学習が終了すれば問題ないですが、その場合でも学習結果を保存していない場合、次回使用する場合はまた同じ時間学習を行うことになります。
このような事態を回避するための方法として、学習したモデルの内容を外部に保存します。
モデルの保存方法については別記事で説明したいと思います。
(リンク予定地)
気を付けるべき点として、保存先をサーバーにする場合には保存したファイルをダウンロードしておかないとやはり消えてしまうので注意してください。
保存先をGoogleDriveにすることができるので、GoogleDriveに保存しておけばサーバーが停止した場合でも保存したファイルは消えません。
また、上に書いた通りサーバーのストレージが毎回リセットされるので、自前の大きめのデータセットなどを扱う場合は結構大変です。
(有名なデータセットについてはTensorFlow等に読み込み機能が付いています。)
こちらも複数回の学習を行うのであればGoogleDrive上に保存しておくのが良いと思いますが、GoogleDriveにアップロードするのも結構時間が掛かります。
またGoogleDriveからデータを読み込むのに結構時間が掛かるようで、大きめのデータセットでは1エポック目の実行時間が結構長くなります。
(私が試した場合では2エポック目以降の実行時間の倍以上かかりました。)
あと、画像データは量が多くなってくると割と容量があります。
GoogleDriveは無料では15GBまでですので、他にも使用したり、複数のデータセットを扱ったりすると容量が圧迫される場合があると思います。
また、使用するモデルが複雑になってくると、保存するモデルデータも結構な容量になってくるので、そちらも注意が必要です。
(これに関しては最新のモデルと定期的なタイミングでのみ保存するなどで良ければ問題ないです。)
このようにいくつか気を付けなければならない点はありますが、一般的なGPUサーバーは有料であることを考えると、無料でこのようなサービスが使用できるというのは破格だと思います。
Googleも実は有料のAIサービスを運営しています。
また、Amazonも有料でAI学習等に使用できるサーバーを使用することができるサービスを行っています。(AWS)
Colabでは不足になった場合には、自前のGPU環境を整えるか、これらのサービスを検討してみるのも良いかもしれません。
Google Colaboratoryの使用方法
使い方とは言っても基本的な使用方法はJupyterNotebookと同じです。
Colabのページから「ファイル」→「ノートブックを新規作成」するか、GoogleDriveで「新規」→「その他」→「Google Colaboratory」でノートブックを新規作成します。
ノートブックを新規作成するとセルが表示されるので、そこにコードを記入して実行ボタン(▶)を押せば内容が実行されます。

ランタイムタイプの変更
ランタイムタイプ(サーバータイプ)の変更はメニューから行います。
「ランタイム」→「ランタイムのタイプを変更」で変更することができます。
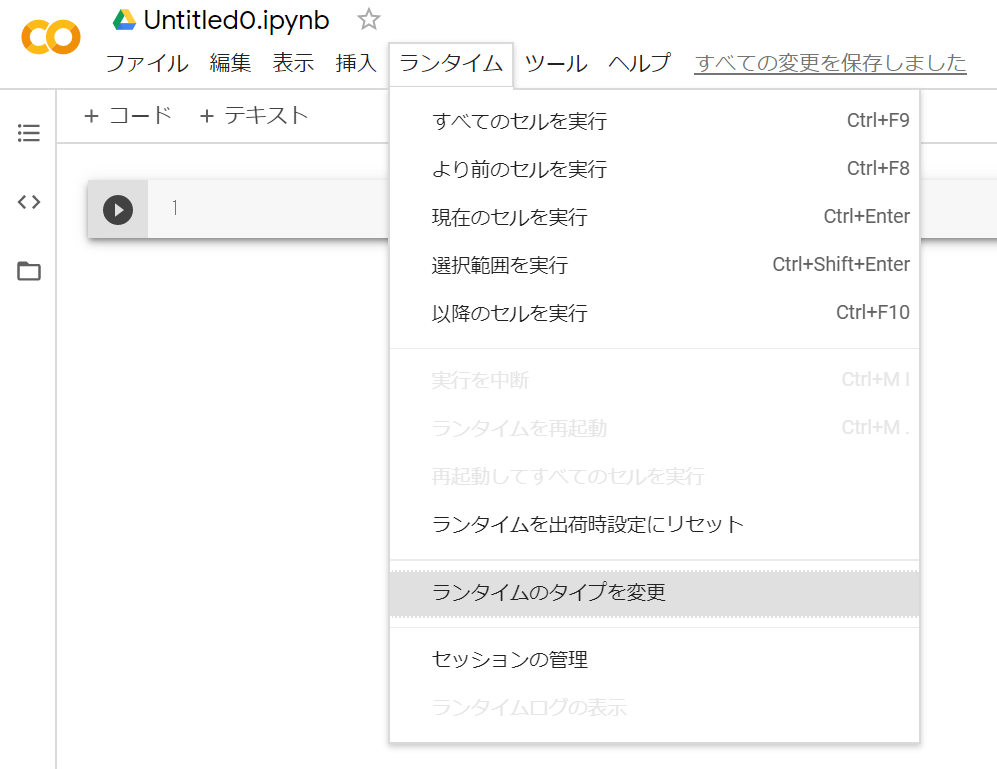
ランタイムのタイプは
- None(CPU)
- GPU
- TPU
から選択します。保存ボタンを押すと新たなランタイムに再接続されます。
TensorFlowでGPUを使用する場合にはtensorflow-gpuをインポートすると書いてあるサイトもありますが、最新のTensorFlowでは自動的にGPUが使用されるようです。
一方でTPUを使用する場合にはソースコードを変更する必要があります。
Google ColaboratoryでTPUを使用する。
以前に紹介した手書き数字認識をTPUを使用して実行します。
変更後のコードは以下のようになります。
import tensorflow as tf
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation,MaxPooling2D,Conv2D,Flatten
from keras.optimizers import Adam
from keras.utils import np_utils
import time
import numpy as np
import os
#モデルを作成する関数
def build_model():
model = Sequential()
model.add(Conv2D(16,(3,3),input_shape = (28,28,1)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Conv2D(32,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])
return model
#ここから実際に実行
if __name__ == "__main__":
#学習用データの読み込みと下準備(MNIST:手書きデータ)
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(60000, 28,28,1).astype('float32')
X_test = X_test.reshape(10000, 28,28,1).astype('float32')
X_train /= 255
X_test /= 255
y_train = np_utils.to_categorical(y_train, 10)
y_test = np_utils.to_categorical(y_test, 10)
resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.experimental.TPUStrategy(resolver)
#モデルを作成。
with strategy.scope():
model = build_model()
#モデルの内容を表示させる。
model.summary()
#学習を実行
time_start = time.time()
model.fit(X_train, y_train,batch_size=128,epochs=20,
validation_data=(X_test, y_test)
)
#(学習にかかった時間を表示)
time_end = time.time()
print("time:",(time_end - time_start))
# モデルの評価を行う
score = model.evaluate(X_test, y_test, verbose=1)
print('loss=', score[0])
print('accuracy=', score[1])変更点は以下の部分になります。
#抜粋
resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.experimental.TPUStrategy(resolver)ほとんどTPUチュートリアルのコピペですが、やっていることとしてはTPUの取得、接続、初期化、実体化(クラス化)という感じだと思います。
また、チュートリアルによるとモデルはstrategy.scope()内で作成する必要があるようですので、上で実体化したstrategyを使用してコードを下記のように変更しています。
#抜粋
#モデルを作成。
with strategy.scope():
model = build_model()実行してみると、意外とGPUに対する優位性が見られませんでした。
この辺のベンチマークについてはまた別途まとめたいと思います。
またちゃんとした確認はしていないですが、keras よりもtensorflow.kerasを使用したほうが実行速度が速そうです。
(KerasはTensorFlowをラップしたパッケージですが、TensorFlow自身もそれと同様のパッケージを実装しているようです。実行速度が違うのは関数名などは同じまま、中身の実装がTPU等に最適化されているのかもしれません。)
一部の機能(今回だとkeras.utils.np_utils)についてはtensorflow.kerasにはないようなので、その場合は普通のkerasを使用しましょう。
以上がGoogle Colaboratoryの使い方になります。
colabは簡単・無料で使用できて、多少複雑なモデルでもGPUを使用して短時間で学習することができるので機械学習入門でとりあえずやってみたいという方には最適だと思います。
ちょっとしたモデルであれば以前紹介したJupyterNotebookをローカルにインストールするのも良いですが、基本的にはColabを使用することをお勧めしたいと思います。
おまけ:GoogleDriveの接続方法
colabでGoogleDriveに接続するには以下のコードをセルに入力して実行します。
from google.colab import drive
drive.mount('/content/drive')実行するとURLとauthorization codeを入力するテキストエリアが表示されます。
URLをクリックしてリンク先を表示するとGoogleアカウントを選択する画面が表示されます。
接続するGoogleDriveのアカウントを選択します。
アカウントを選択すると文字列が表示されるので、そちらをコピペしてもとのノートブックに表示されているauthorization code入力用のテキストエリアに入力します。
成功すればColabの左側にあるファイルのタブにGoogleDriveの内容が表示されます。
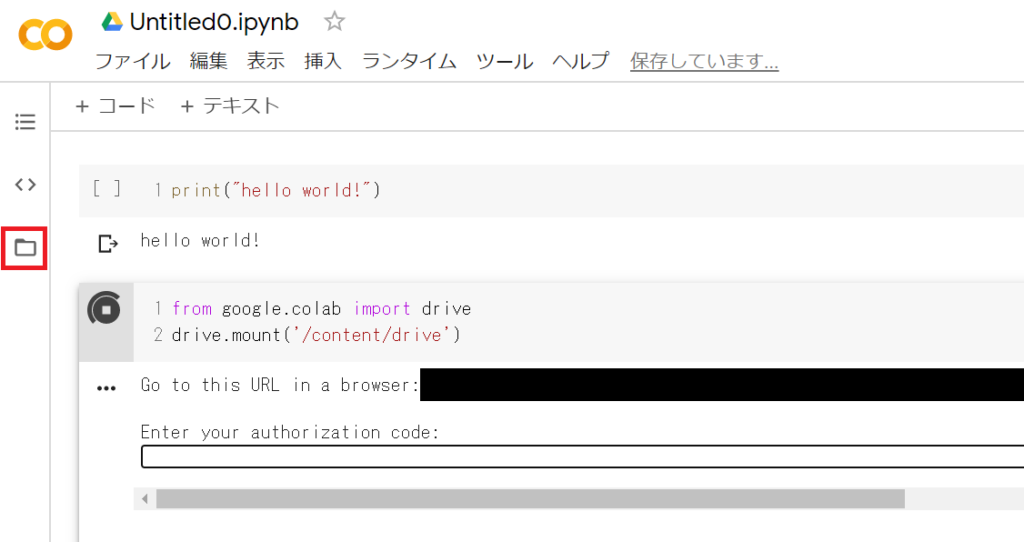
接続されたGoogleDriveはローカルフォルダのように使用できるので、例えば
#抜粋なので動きません。
open("/content/drive/My Drive/〇〇〇.jpg","r")のような形でパスを指定して使用することができます。